- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【原创】化工过程控制的实践 -- 润树
家园 【原创】7. 神经网络及其应用 神经网络(Neural Network)也可看作是人工智能的一个分支。如图7.1所示,它模仿生物神经系统的网状结构,对系统的输入信号进行逐级处理而产生输出信号。
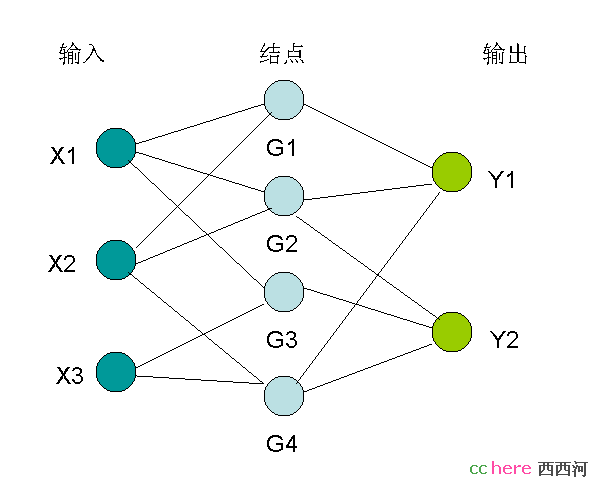
图7.1 神经网络系统的概念图示
作为概念的说明,这是一个只有输入X1 … X3,结点G1 … G4,输出Y1和Y2的三级神经网络。显然,更为复杂的系统是输入信号更多,结点和结点级数增加,输出信号也增多。无论简单还是复杂,神经网络与传统的信号处理系统的区别是在输入和输出之间加入了结点。网络中的连线是表示点与点之间具有乘法关系的加权系数。可以这样来理解它们之间的关系,这就是,中间结点是各输入的加权之和,而输出又是各结点的加权之和。用数学式表示出来就是:
G(k) = Sum [ M(i) * X(i)],k = 1 … 4;i = 1 … 3
Y(j)= Sum [ N(k)* G(k)],j = 1,2;k = 1 … 4
从数学上来说,这里的输入与结点之间和结点与输出之间都是线性关系。但经过中间结点的线性转换,输入与输出之间就可能不是线性关系了。因此我们可以说,神经网络把本来是非线性的输入输出函数,通过中间结点,转换成了线性函数来处里。而对于线性函数,我们可以方便地利用数理统计的方法来改变各加权系数,对某个目标函数,比如以函数表示的输出值与实际观测的输出值之间的平方差达到最小值。这就是用神经网络来建立输出与输入模型的优化法。
如果将这种方法用于一个实时过程,其输出(观察值)是不断变化的,那么我们还可以将观察到的输出误差反馈到输入级,使原来建立好的模型系数能够得到修正,形成一个具有自我学习的系统,或称自适应系统。当然,在实时过程中,输入与输出之间还存在动态关系,神经网络系统通常用純滞后和一阶滞后时间常数来描述这种动态关系,并且对其进行优化。
像其它人工智能的应用一样,神经网络系统需要很强的计算功能,因此在上世纪90年代初才开始得到普遍的应用。在过程工业领域,地处德州奥斯汀的Pavilion Technology 公司以Process Insight 软件产品一炮走红,很热火了一段时间。它们那时的口号是从过程数据里淘金(gold mining from process data)。在ISA的年度贸易展时,支起一个大棚,在荷枪警卫的保护下,把一锭二十几磅的纯金拿出来展示,认每个参观者抱着它照相,引诱人心。照过相后,参观这就看他们演示用自己的软件怎样从一大堆杂乱无章的历史数据中,用神经网络模型来预测过程输出值与观察值天衣无缝的拟合。此后,他们很卖了一些软件,主要用于过程中成分分析的软测量。由于在线分析仪表的高价格高维护费,此种软测量以过程中的其它变量,像温度,压力等作为输入信号,用神经网络来计算过程中的成分值。当然,既然可以建立过程的实验模型,用神经网络来直接进行过程控制也就顺理成章了。因此,Pavilion公司也有自己的模型预估控制和实时优化应用产品。
过程控制软件开发的领头羊Aspen Tech看神经网络如此热门,当然也不甘寂寞,于是也在市面上去买来一家公司,打出自己的神经网络产品,名之为Aspen IQ,专门用于软测量。下面我们就来看一个它的应用实例。
在第5章里,我们举了一个用数理模型来计算某化学反应器中酸组分不成功的例子。其失败原因主要是模型中缺乏过程的动态因子。Aspen IQ对每个输入信号都加入了純滞后和一阶滞后时间常数,因此用同样的过程数据,获得了一个较好的预估模型。
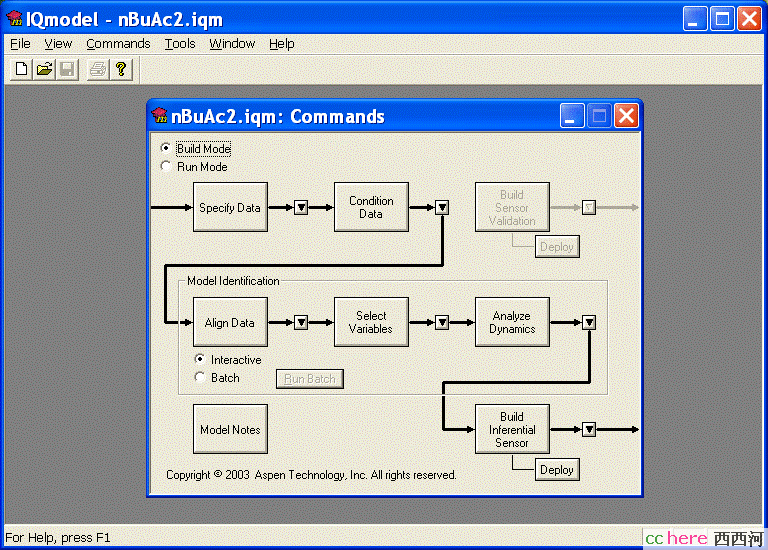
图7.2 Aspen IQ的建模面板
图7.2是Aspen IQ的建模面板,这是基于图像和表格的人机界面。在输入原始数据文件后,可以对数据进行一些过滤处理,去除某些不合理的数据。然后是选择输入变量,可以人为地选择, 也可以让软件根据各变量的灵敏度分析来自动选择,这一步很关键。我的经验是,使用者对过程的认识通常要较人工智能正确一些,因此人为选择一般要优于自动选择。对于本例,我选择用反应塔的某塔板温度和塔压差作为输入变量,而不选择塔底的反应器温度。这是因为,反应器里面有好多种组分,温度不能反应某单一组分的变化。但是塔底酸组分的变化,却会影响到被蒸发到塔板上的酸,从而使该塔板的温度发生变化。这里选择塔压差作为输入变量的原因是,即使塔板组分没有改变,塔板温度也会随压力而变化,因此必须对温度进行压力补偿。在对所建模型没有良好预计的情况下,可以运行程序对不同变量的组合所获得的模型结果进行比较来确定一个较好的组合。一个需要注意的问题是,不要单纯为了提高模型精度而加入过多的输入变量。对于神经网络,增加变量通常都会改善模型精度,但有些输入变量可能是线性相关的(比如两个邻近塔板的温度),有些则与输出变量完全没有或只有很低的相关性,其次是对测量仪表可靠性的要求也增高。
接下来是运行程序来寻找输入变量与输出变量之间的动态关系。在本例中,找到塔板温度与反应器酸组分之间的纯滞后是43分钟,一阶滞后时间常数是9分钟。这就是说,反应器酸组分改变以后,并不会马上引起塔板温度变化,而是要等蒸发到塔板上的酸积聚到一定程度以后,才会引起温度变化,当然,这里面也包括感温元件的灵敏度和时间滞后。
以上步骤完成后,就可以运行建模程序。Aspen IQ提供4种方法建模,即线性偏最小二乘法(linear partial least square),模糊非线性最小二乘法,偏最小二乘法与神经网络混合法,纯神经网络法。可以尝试用所有的方法来建模,然后加以比较。但一般地说,偏最小二乘法与神经网络混合法的使用较为普遍。
图7.3是本例模型的结果,图7.4是模型预估值与测量值的比较。这不是一个很理想的模型,但结果还算是差强人意。
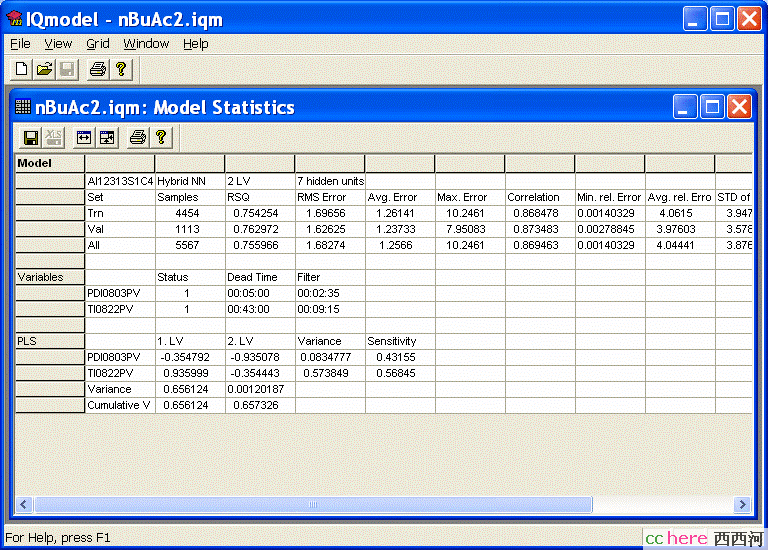
图7.3 模型结果
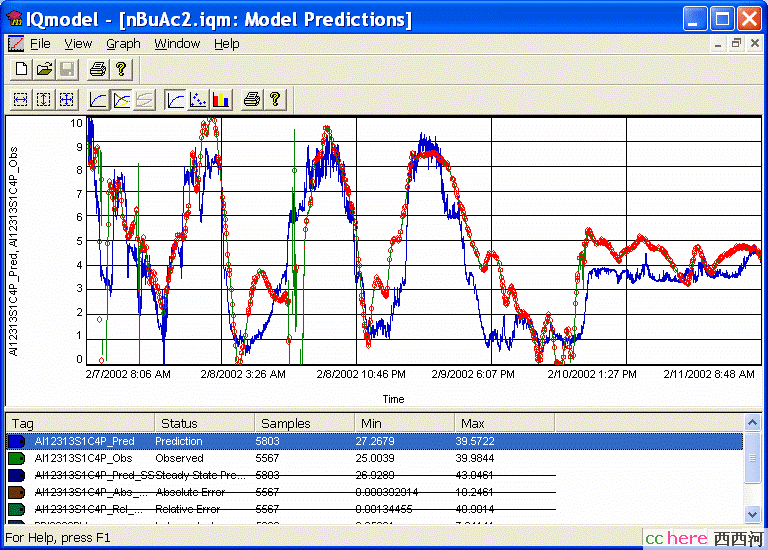
图7.4 模型预估与测量值的比较
关键词(Tags): #化工过程控制, 元宝推荐:橡树村,
本帖一共被 1 帖 引用 (帖内工具实现)家园 看上去跟神经传导是有些相似 再接再厉
家园 【原创】6.专家系统及其应用 虽然人工智能是在数字计算机发明以后才得到很大的发展,但这个概念在一百多年前就出现了。而专家系统作为人工智能的一个重要分支,则完全是计算机出现以后的产物。它们是一类具有专门知识和经验的计算机智能程序系统,一般采用人工智能中的知识表示和知识推理技术来模拟通常由领域专家才能解决的复杂问题。这里的专家,可以是任何在该领域长期工作而积累了丰富知识和经验的工人,农民和技术人员,而不必是有高学位的饱学之士。人们对人工智能究竟能走多远一直持怀疑的态度,其命运忽天忽地难以确定,但专家系统实实在在为人类解决了很多问题,却是无可置疑的。
不同的领域有不同的专家系统,目前应用较多的领域包括医学,教育,会计,金融服务,过程控制,制造业等等。我们日常生活中也常和它们打交道,像汽车故障自动诊断,语言教学程序,报税软件,以至汽车上的全球定位导航系统,等等,都可看着是专家系统的应用。
既然是模拟专家来解决问题,那当然就要模拟人通过大脑用知识和逻辑来进行推理的过程。专家系统里的知识表示是通过知识库来实现的。知识库不同于一般意义的数据库,里面所存贮的知识,是该领域里的专家知识经验的积累,常常是用一些框架,规则和语言符号系统把它们表示出来。比如一个用于化工过程故障诊断的专家系统,它的知识库里面,就可能包括这样一些框架和规则:
1.中间贮罐A的体积贮量是它的液位百分比乘以它的最大贮量。
2.如果管道A上的液体流量阀门开度是0%,那么该管道里的流量是0。
3.如果管道A上的液体流量阀门开度是100%,那么在其两端压差不变的情况 下,该管道里的流量达到了最大值。
4。如果精馏塔A的塔压大于0.5个工程大气压就处于液泛操作状态。
5.精馏塔的塔顶和塔底出口流量之和必须等于其进料流量之和。
6。焚化炉的进料管道中的有机物成分与氧气成分在某组合范围内将形成自燃状态。
为了诊断/预报出生产中的故障,这个专家系统必须实时运行,即通过该系统与过程的控制系统的接口获取实时数据,来进行分析判断。比如,运用以上知识库,可作以下判断,并据此采取相应措施:
1.如果中间贮罐A的进口流量中断,那么系统可以根据其现有贮量和其出口流量来计算还能向下游过程提供多长时间的物料。
2.管道A下游将受到何种影响。
3.该过程已出于约束条件操作,应采取什么措施解除此约束。
4.当塔压差接近0.5个工程大气压,报警或采取其它措施。
5.如物料不平衡,超出某预设限度,显示仪表故障报警(还需要其它信息才能判断究竟是哪个仪表的故障/误差)。
6.在焚化炉的进料管道中的有机物成分与氧气成分的组合接近自燃范围是报警或采取预设措施。
当然,实际的系统要复杂得多,可能有成千上万的框架和规则,他们之间还会构成一定的关联,可能采取的措施和解决方案也是多样的。不过这只是增加了系统开发的难度和所需的时间,只要投入人力物力,总是可以实现的。所幸的是,在计算机编程技术高度发达的今天,人们不必再去写针对特殊系统的源程序,而是利用针对普遍应用的商业软件开发系统。在过程工业领域,Gensym 公司的G2得到了较为广泛的应用。作为实时通用专家系统的开发平台,它的概念框架说明如图6.1所示。
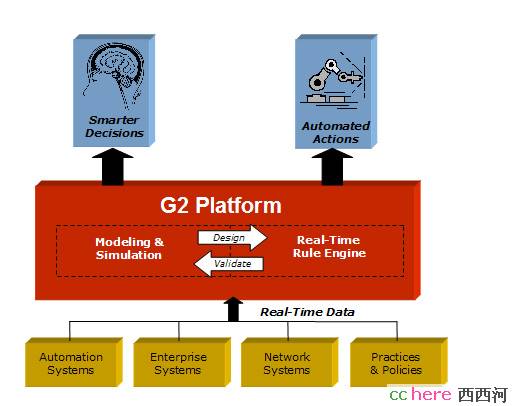
图6.1 G2系统框架图
G2旗下还有针对不同工业应用的软件产品。比如G2 Optegrity,适用于对化工生产中的非正常操作状态进行预估,诊断,和提供解决方案。作为一个简单的应用,我们来看一个对加热炉的燃烧效率进行检测诊断的专家系统 (由Gensym的用户提供),如图6.2所示。
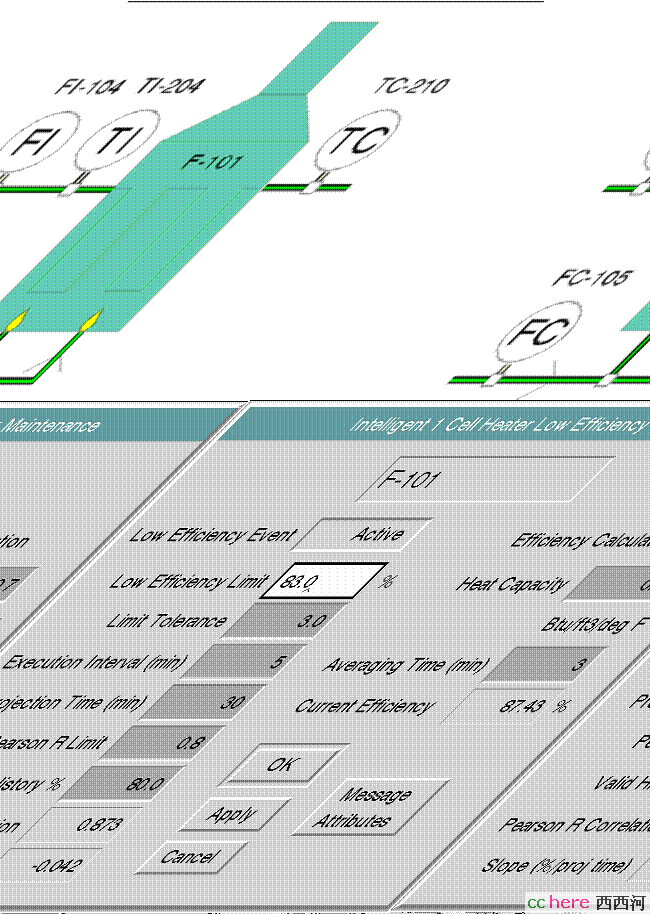
图6.2 加热炉燃烧效率监测系统
该加热炉以天然气作为燃料,与空气中的氧气产生燃烧反应,对通过炉体的管道中的物料加热,使其达到所需温度。从天然气的流量测量,可以计算出它在单位时间内提供的热量。同时,可以由过程物料的流量,入口和出口温度计算出得到了有效利用的热量。由于燃烧炉的烟道气要带走一些热量,有效利用的热量必然要小于燃烧热量,它们的比值就是作为衡量加热炉工作的热效率。老式的燃烧炉,一般都是通过手动调节烟道气的档板的开度,来改变进入炉膛的空气流量。空气流量如果太小,将造成天然气不完全燃烧的现象,不但会使热效率降低,而且可能带来安全隐患。相反,空气流量太大,烟道气就会带走更多的热量,同样会使热效率降低。现在这个专家系统实时地计算出热效率,并且追踪它的变化趋势,就可以向操作工提供有用的信息,比如:
“加热炉F-101现在的热效率是85.4%,预计在30分钟内将降低到83%以下。请检查炉膛压力,烟道气氧气含量以及档板开度,以确定是否可以通过改变空气流量来改善热效率。”
从这里我们可以推测,这个燃烧炉没有在线烟道气氧气检测仪。如果能安装一个这样的检测仪,而且可以自动调节空气流量,那么设计一个闭环控制回路,将烟道气氧气控制在一个最低值,即可自动将燃烧效率保持在理想状态。
关键词(Tags): #化工过程控制,家园 为什么是TC而不是FC? 家园 你是指加热炉上的TC吗? 那是控制被加热的物料的出口温度,应该是与天然气的流量控制形成串级控制。被加热物料也许有,也许没有流量控制(FC),取决于它的上游和下游的过程以及控制的整体设计。
家园 这个“专家系统” 是不是跟那个“象棋师”的原理差不多?不知道国内有没有人搞过“围棋师”,可能太复杂了。
家园 【原创】5.数理统计与化工过程控制 统计的过程控制(Statistical Process Control, SPC)在制造业是一个很常见的词。这里的过程,并非单指化工的,而是泛指一切具有因果关系的生产/制造程序。人们用数理统计的理论对这些过程进行分析和控制,从而获得有益的结果。
说起数理统计,我们多数人都不陌生,它不但在工程技术领域广为人知,而且也广泛地应用于社会科学领域和我们的日常生活中。我们知道,科学理论是对世界上那些具有确定性的事物的研究而得出的一般规律,由这些规律所描述的事物的现象和特性是可以确切不移地被重复观察或再现的。而数理统计的理论所研究的对象和由此研究所得出的结论,却大多具有某种程度的不确定性。用来描述这种不确定性的概念,就是我们耳熟能详的概率。
数理统计在化工过程控制的应用中主要有两方面的功能,一是它的描述性(descriptive),即对过程变量本身的变化特性,比如平均值,标准差等,进行定义和计算;二是它的推测性(inferential),即将一个或多个变量输入某个数学模型,比如多项式,来对另一变量进行回归计算。前者的作用是显而易见的,而后者可以帮助控制工程师找出影响过程变量变化的因数,从而对某些不易直接测量的变量进行推测计算,或者通过改变这些影响变量来改善/控制被影响变量的品质 (这也是盛行于工业界的6倍标准差-Six Sigma的主要内容)。将这些功能在计算机上实现的,有通用的数理统计软件,象Minitab,也有专门针对化工过程的建模软件,像Aspen IQ,Pavilion Process Insight等。即使像MPC的建模软件,也运用了数理统计的计算技术,只不过针对过程变量的动态特性加进了时间因数而已。
改善被控变量的品质,主要体现在减小其标准差。一般地说,几乎所有被控变量的平均值,都等于或很接近于其控制设定点。但它们的标准差却可以有很大的差别。控制效果好的,标准差就小,反之就大。而减小标准差,在多数情况下,都可带来生产效益的提高。比如一个化学反应器要防止它在自燃点的条件下操作,通常是计算和控制它接近自燃点的程度,当其低于预设下限值时,装置就会自动保护停车。如果这个值的不良控制导致其上下波动较大,就只能把控制点设定得离下限值较远的地方。而这样做往往是以牺牲生产效率为代价的。因此,如果能够减小其波动幅度(以标准差来衡量),那么就可以将控制点设定在离下限值较近之处。又比如被控变量是精馏塔的产品的杂质度时,通常希望它能接近该产品的指标上限,这样可以降低分离要求,从而减少单位产量的能源消耗。下面这个数据曲线显示,是用来说明这个概念的:左半部分标准差较大,平均值较小;右半部分降低了标准差,控制平均值可安全上移。
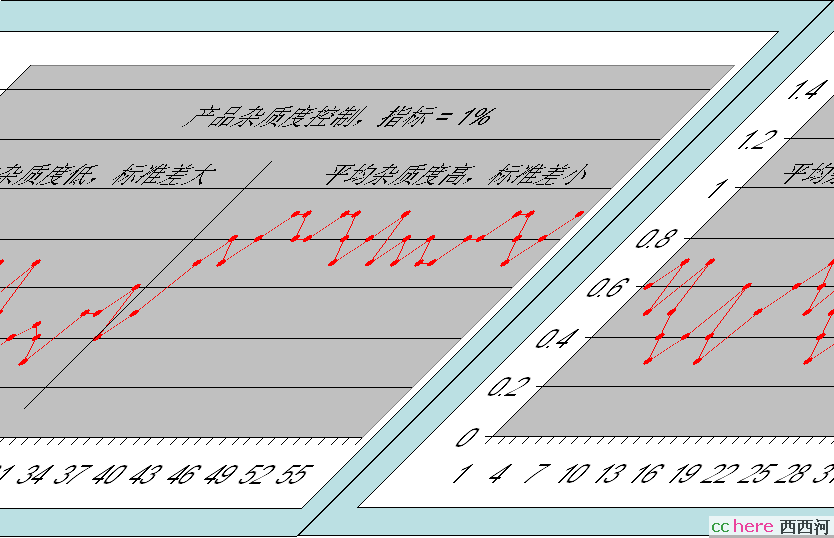
图5.0.1 改善变量变化特性的图示说明
5.1 数理统计软件Minitab
Minitab的功能很多,但归纳起来还是在对变量进行定性描述和推测计算两方面。
我们来看一个由在线分析仪得到的某反应器的物料浓度变量,它的典型数理定性描述如下所示。从这个描述我们可以知道,它的5097个数据近似于正态分布,平均值是33.44%,标准差是4.004%。还有其它一些数理特性,不赘述。
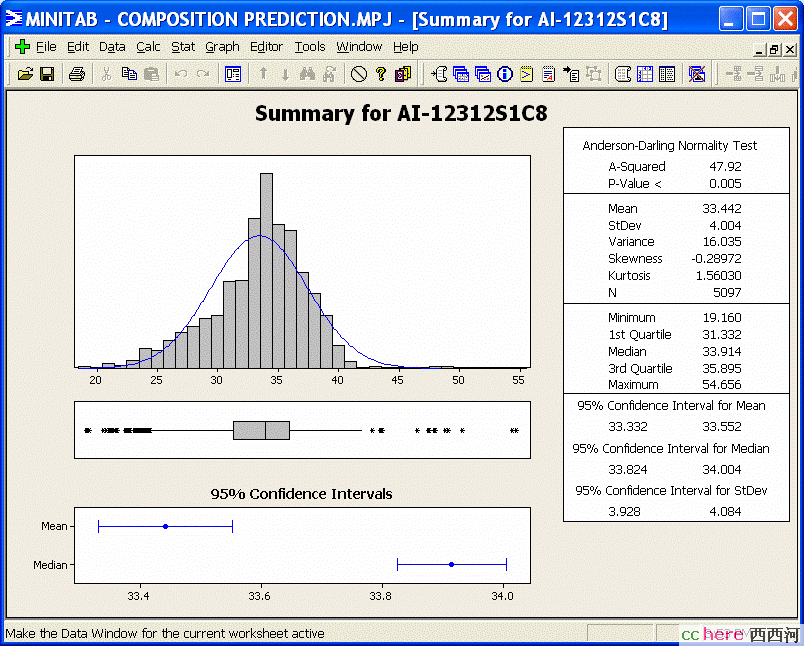
图5.1.1 某变量的数理特性
这台在线分析仪可靠性不高,其中一个主要因数是采样管道常被物料中的固体颗粒堵塞。为此,该装置的控制工程师拟用Minitab建立模型,由其它过程变量来推测计算该物料浓度。然而,经过多种变量的组合,均无法找到一个较好的模型。下面的这个模型是最好的一个,但其标准差S仍很高,不能适合工程需要。
该模型是:
AI123 = - 3566 - 0.000788*TI06 + 30.5*TI08 - 0.0636*TI08S
+ 0.408*PDI08
式中,AI123是浓度,TI06是反应塔塔底温度,TI08是塔板6温度,TI08S是塔板6温度的平方项,PDI08是塔压差。
Predictor Coef SE Coef T P
Constant -3565.6 431.5 -8.26 0.000
TI06 -0.00078751 0.00002240 -35.16 0.000
TI08 30.484 3.705 8.23 0.000
TI08S -0.063624 0.007943 -8.01 0.000
PDI08 0.4076 0.3721 1.10 0.273
S = 3.05020 R-Sq = 42.0% R-Sq(adj) = 42.0%
Analysis of Variance
Source DF SS MS F P
Regression 4 34339.9 8585.0 922.75 0.000
Residual Error 5092 47374.4 9.3
Total 5096 81714.3
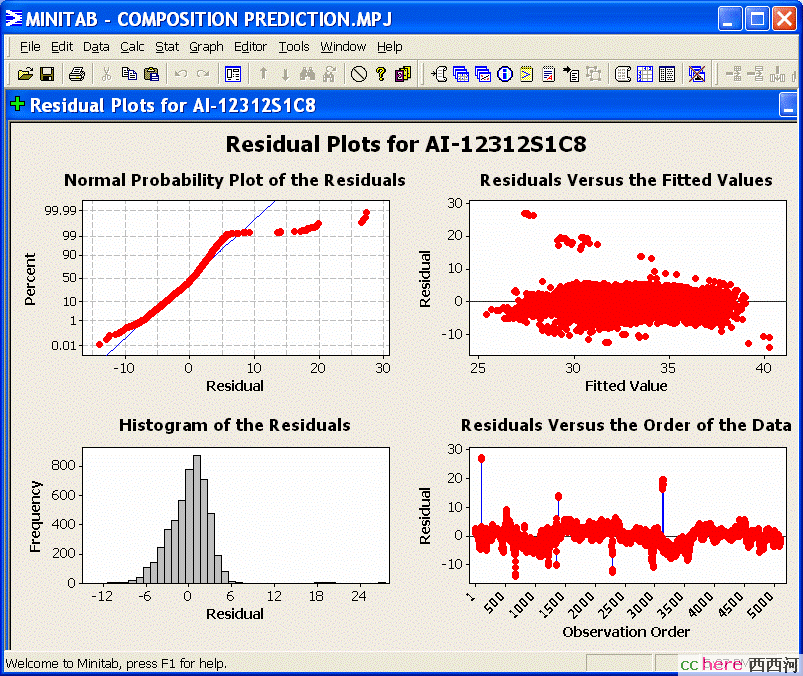
图5.1.2 模型结果的图像描述
这里建模不成功的原因在于,Minitab这样的数理软件只适合于处理静态数据,即各变量之间的关系,不受时间变化的影响。对于化工类的过程,如果对变量的数据进行了时间足够长的平均值计算,而排除了它们之间的动态关联,那么用Minitab来建立数理模型才是可行的。
当然,要找出一个过程多变量输入对单变量或多变量输出之间的静态关系,一个系统性的方法是,用Minitab提供的阶乘实验(factorial design)等实验设计(Design of Experiment, DOE)步骤,对过程进行双位式的扰动,记录下各输出对这些扰动的静态响应值(排除动态关联),再用Minitab的相关分析(correlation analysis)和回归分析(regression analysis),来辨别输出变量对各输入变量的敏度。这种方法被6倍标准差的黑带大师(Master Blackbelt)大为看重。但是,对于真正了解过程的工程技术人员来说,这种方法有点像杀鸡用牛刀,小题大做了。
关键词(Tags): #化工过程控制, 元宝推荐:橡树村,爱莲,家园 今天培训刚提到SPC,回来就看到这个贴了。 问一下老师,minitab是不是自己用matlab都可以编出来?




