主题:openAI又迭代出GPT4了,这次支持图片的理解能力了 -- 亮子
家园 openAI又迭代出GPT4了,这次支持图片的理解能力了 -- 有补充 想起来六七年前有个说法:中美之间传统工业因为需要积累差距很大,反倒是人工智能,互联网之类的新兴行业,中美差距不大。现在这话可能要反过来了。随着美国去工业化跟在人工智能上的加大投入,此消彼长,中美可能甚至传统工业比人工智能的差距要小


 通宝推:心有戚戚,作者 对本帖的 补充(2)
通宝推:心有戚戚,作者 对本帖的 补充(2)家园 不单单是图形理解能力,基本的文本理解能力比前代都有不小提升 -- 补充帖 对手的长处要正视,任何新技术莫看可能仍然有一堆这里那里的缺点,只要不断迭代下去缺点总会解决的
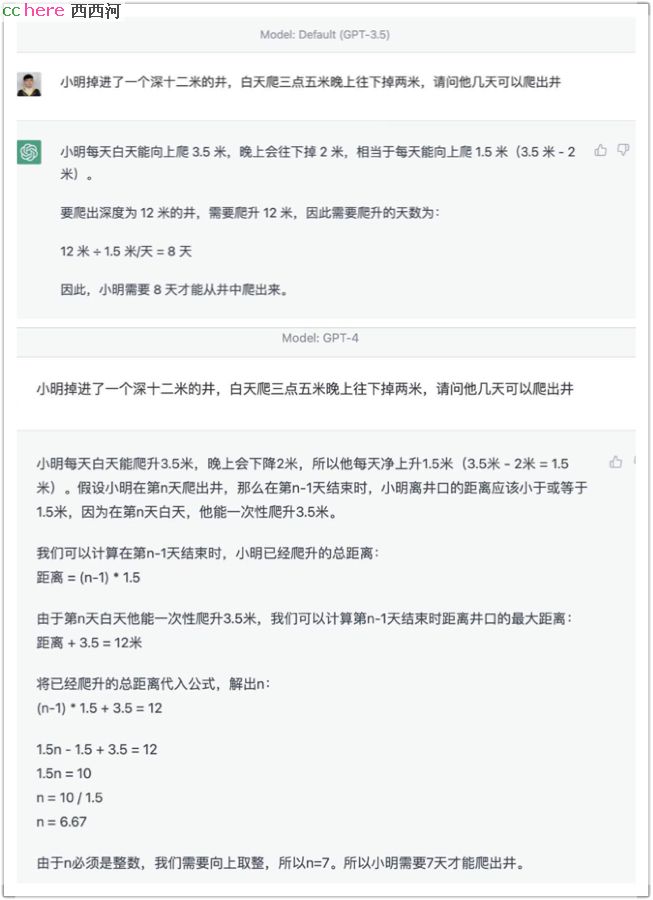
家园 转自鼎盛,文心一言有人测试了,写代码不行,逻辑性不行 -- 补充帖 当然,再烂总归是自己做的,比亚迪跟华为的初代产品也是烂的不行,只要肯下功夫迭代总会变好的。
【被迫上场?我们全方位测试了文心一言,只能说_____。【差评君】】 https://www.bilibili.com/video/BV1hY4y1X7Cs
这里分类讨论一下二者的表现:
1.写一首以猫为主题的打油诗 文心一言:生成了一首类似七言诗的作品,语感上更接近我们印象中的古诗,但是没看出和猫有什么关系,并且用了一个不存在的典故。 gpt4:生成了一段真。 打油诗,不咋押韵,用很白话的语言写了猫,文学性不咋地。 这个环节其实我觉得半斤八两。
2. 写代码 让他们写一个点击会变色的按钮。 文心一言:生成了一段js代码,并且在要求它补充html和css的时候失败。 gpt4:直接生成了html+css+js代码,粘贴进浏览器就能运行,实测可用。 让他们写一个2048游戏 文心一言:生成了一段2048的js代码,因为主持人不是程序员,于是丢给了gpt4。 gpt4:直接指出了文心一言的代码变量名命名错误(用数字开头),数组上限错误(应该从0到2047而不是2048),让它修正后它修正了,并且指出文心一言这段代码并不是一个2048游戏代码(笑死,嘲讽拉满)。 让他自己写一个,它同样生成了一个html+css+js的2048游戏代码,主持人复制到txt里改个后缀就能玩了,就是有点简陋,并且新生成方块的逻辑是随机的。 把gpt4的代码丢回文心一言:文心一言并不能解析代码是什么意思,而是直接把gpt4的html给生成显示了…… 这算不算一个攻击漏洞 总之,写代码,被薄纱。
3.写文章 让他们写本手、妙手、俗手那个高考题。 文心一言:文章全篇都是围绕围棋本身,更像本手、妙手、俗手的名词解释,主持人复制到浏览器搜索可见大片重复文字。 gpt4:逻辑吊打,从围棋术语引申到人生态度,至少是真的在写作文,不过这里主持人就没查重了,感觉不太严谨。 林黛玉倒拔垂杨柳 文心一言:开头还行,写一半逻辑没了,“用一根竹竿然后林黛玉爬上去然后倒拔了柳树”,所有人都没看懂林黛玉怎么拔的。 gpt4:试图用文学性取胜,有很多环境、人物语言描写等,但是理解成了把其中一个柳枝倒过来,操作是用红丝带拴着一个柳枝使它倒过来。 孙悟空穿回三国会发生什么 文心一言:这次老老实实列了四个可能性,说孙悟空有可能会和三国的人物相识,从而发生xxx故事。 gpt4:相比之下更厉害的地方在于,它会结合孙悟空的个人能力,比如头脑聪明,法力强大,再结合个人能力分析他在三国会怎样。 我也是看了gpt4的答案,才像弹幕里说的意识到,相比之下文心一言的回答可以把孙悟空换成隔壁小王,也没啥区别。 总结:逻辑性应试性的文章chatgpt吊打,脑洞类两个有时候都抽风。
4.逻辑陷阱 类似于刘备和刘秀什么关系,爸爸和妈妈能不能结婚,番茄炒西红柿怎么做这种问题,文心一言的表现和gpt3差不多,会胡说八道。 gpt4基本都能识别出陷阱。 当然这个也是gpt4这次重点优化的一个部分,表现被薄纱我觉得没啥可惊讶的。
5.数学题/逻辑题 用1234做24点 文心一言:傻了,直接出bug,大段无法理解的文字。 gpt4:先给你解释怎么一步步生成的24点,最后列出算式。 用3L和5L的水桶称出4L水 文心一言:3L水桶装满,倒进5L水桶里。 没了,摆烂了。 gpt4:第一步.3L装满,倒进5L水桶 ; 第二步 3L装满再倒进5L水桶,直到5L水桶装满; 第三步 把5L水桶倒空; 第四步 把3L水桶剩下的水倒进5L水桶 (此时3L水桶里还有1L水); 第五步 3L水桶接满,再倒进5L水桶(此时有4L水) gpt4不仅对了,还会分步骤,甚至会给括号解释内容。 被薄纱 另外直播快结束的时候好像还测了一个开根号的问题,文心一言又bug了,疯狂输出的那种bug。
6.辩论赛 让他们扮演一个辩手,辩论“近墨者黑”和“近墨者未必黑” 文心一言:对不起,我不能扮演辩手和你辩论。 gpt4:好的,我将作为辩手和你辩论。 然后围绕“近墨者未必黑”,从个人选择和家庭影响两个缅方面展开了论述。 严格按照总-分-总模式形成了论点。 把gpt4的论点粘贴给文心一言试图让他反驳:好的,我来反驳。 然后把gpt4的论点复读机了一遍。 总结:被薄纱
7.文生图以及文字转语音 文心一言:文生图没有一次达标的,让生成围棋棋盘,中间硕大的国际象棋; 让生成西红柿炒蛋,出来毫不相关的图; 让生成林黛玉倒拔垂杨柳,直接拒绝生成。 文字转语音:多次尝试关键词后,成功了。 不过恕我直言,这和其他文字转语音软件有啥区别啊…… gpt4:没有这个功能,被薄纱了呢(狗头。 没有测gpt4的多模态读图功能,虽然我觉得这才是多模态的核心。
8.上下文理解 文心一言:上下文理解稀烂,很多时候两句话之间都无法形成记忆,更别说连续对话了。 gpt4:这还用赘述么,3.5时代就可以一直callback没问题了。 总结: 测到最后主持人绷不住了,总结文心一言的优势的时候说它有gpt不具备的文生图和语言功能,大家自行评判。
其实chatgpt出现之所以惊艳众人,就是它强大的逻辑归纳能力,以及上下文语意理解能力是划时代的,和之前的人工智障观感完全不同; 再加上强大的代码生成能力,不止能写,主要是还能理解,论文类也不在话下,这种类似的应用就可以解放生产力。 文心一言的逻辑能力和上下文理解可以说还是很初级的水平,对于语意的理解也很一般,更别提整合信息的能力。 我们当然可以说给国产技术一些时间,关键是,openai给不给他们时间呢? 发布于 2023-03-16 22:46
家园 继续抄华为2021年初的作业 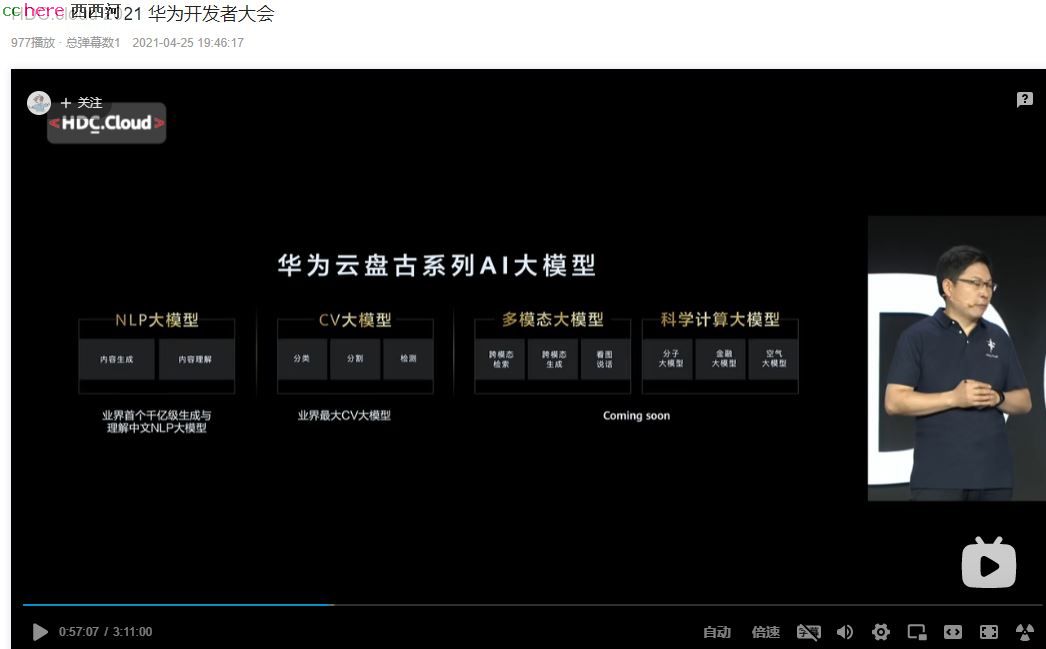
CV大模型就是图片处理。还差多模态和科学计算没抄。
CV大模型华为早已经在无人机拍照摄像巡查供电线路一类中实际使用了(AI根据图片判读可能故障隐患)。

3年前大英经济学人就把科技战写作华为的科技冷战,诚不我欺。
家园 人工智能要看怎么理解,中国强的是工业应用这块 也就是说中国是需求推动的。比如说中国的快递,无人化港口,智能矿山,智慧城市,人脸识别等。只要有需求的领域,中国推进是很快的。
美国国防部副部长罗伯特·沃克(Robert Work)说过,美国在人才库、硬件和算法方面具有很小的优势,但中国在积累数据、部署应用程序和整合不同功能方面走在了前面。
GPT这个因为不是市场需求所以中国之前没人愿意花钱探路。现在这条路被美国走通了,中国跟上应该是很快的。
通宝推:外俗内正,家园 肯尼亚数据标注“血汗工厂” ChatGPT光环照耀不到的隐秘 《科创板日报》2月11日讯(编辑 邱思雨) 能聊天、代写论文、作诗编程样样不在话下,ChatGPT发布不到一周便收获了百万用户。其锋芒从美国席卷到中国,但在地球另一边的非洲大陆上,一群为OpenAI工作的外包数据标注员,曾遭受过非人的精神折磨。
坐在电脑前、阅读一段文本、给出相应的标注、紧接着切换到下一段……这就是数据标注员的日常。在这场席卷中美两个市场的资本狂欢中,他们是边缘化的、被遗忘的却又至关重要的一个群体。
据美国《时代周刊》报道显示,为了训练ChatGPT,OpenAI雇佣了时薪不到2美元的外包肯尼亚劳工,他们所负责的工作就是数据标注。
数据标注的工作流程包括数据标注、打标签、分类、调整和处理等,是构建AI模型的数据准备和预处理工作中不可或缺的一环。对于ChatGPT这样的语言模型,如果没有人工标注来筛除一些不恰当的内容,那么它不仅会给出一些错误的信息,更会对用户造成心理不适。
更何况,类似ChatGPT这样的预训练模型在训练过程中需使用的数据样本较多,数据标注的需求较高。
那么如何规避上述问题,筛查出有害内容呢?OpenAI效仿了Facebook等社交媒体公司的做法——构建一个额外的AI模型,向它提供暴力、仇恨等带有攻击性的言论,从而让它学会识别相应内容。这样的模型会被内置到ChatGPT中,帮助后者过滤掉一些有害的文本。
在这个过程中,需要大量的人力来给攻击性言论做标注。于是,OpenAI在2021年底与一家外包公司Sama达成了合作。两者签署了三份总价值约20万美元的合同,OpenAI向Sama发送了数万个文本片段,包含大量的有关谋杀、自残、虐待甚至其他更加不堪的内容。Sama公司的每一个数据标注员的日常工作流程就是阅读文本并为其添加相应的标签。
“那是酷刑”
Sama是一家主营数据训练的公司,专注于为人工智能算法注释数据,客户包括沃尔玛、谷歌、通用汽车和微软等多个海外大厂。
Sama官网
据《纽约时报》早年报道和维基百科注释,Sama标榜自己为一家有道德的公司:“Sama的使命是在数字经济时代为低收入人群增加就业机会。”此外,公司声称已帮助超五万人摆脱了贫困。
而Sama数据标注员的真实工作情况如何?据《时代周刊》披露,根据资历和表现,Sama为OpenAI雇用的数据标注员的实际工资约为每小时1.32美元至2美元。有三位员工透露,在Sama,三十余名工人被分成三个小组,他们每九小时轮班阅读和标记150至250段文字,每段文字大约100词到1000词不等。
上述被采访员工均表示,这份工作给他们留下了“精神创伤”,虽然他们能够参加公司组织的团体心理辅导,但辅导并没有提供任何的帮助。此外,由于Sama对员工工作效率要求极高,所以公司很少组织心理辅导活动。有员工曾提出想与心理辅导员一对一进行咨询,但被Sama的管理层拒绝。
其中一位数据标注员坦言,在阅读了一些过于不堪的内容后,他反复出现幻觉。“那是酷刑。”他表示,“整个一周,你会反复的阅读这样的内容。等到周五,你会不停想象与它相关的场景。”
Sama的回应
低薪、高强度、创伤性的标注工作折磨着肯尼亚工人的身心。对于来自《时代周刊》等媒体的“控诉”,Sama回应外媒Quartz称,其支付给标注员的薪资几乎是东非其他内容审核公司的两倍,并给员工提供福利和养老金,并声称这样的待遇在东非并不常见。
据了解,肯尼亚并没有统一的最低薪资规定。但在内罗毕(肯尼亚首都),一个接待员的最低时薪是1.52美元,而Sama的数据标注员最低薪资仅为1.32美元。在Sama与OpenAI的合同中,OpenAI向Sama支付每小时12.5美元的工作费用,是Sama数据标注员最低薪资的9倍以上。
Sama的发言人还表示,在每九小时的轮班工作里,标注员只需要标记70段文字,而不是上文所述的150至250段文字。此外,数据标注员的税后时薪为1.46美元至3.74美元。合同中每小时12.5美元的工作费用覆盖了包括基础设施、质检、管理团队薪资等在内的所有成本。
针对员工遭受心理折磨的情况,Sama的发言人则声称,公司十分重视员工的心理健康。“我们为员工提供一对一的心理咨询。在审核、标注工作过程中,员工可以随时退出工作,且不会受到任何的惩罚。”该发言人补充道,“员工标注有害内容的时间是有限的,敏感信息会有专人处理。”
违法、解约和失业
2022年2月,OpenAI与Sama加深了合作,OpenAI要求Sama收集数千张暴力和黄色的图片,其中包括一些违法美国法律的内容。据《时代周刊》、《布鲁塞尔时报》等外媒报道,当月,Sama给OpenAI交付了一批1400张图像的样本,后者向前者支付了787.5美元。
但很快,两者的合作破裂。Sama在一份声明中表示,有关图像收集工作的原始合同并未包含违法内容,但工作开始后,OpenAI向其发送了一份附加说明,其中提及到一些涉嫌违法的内容。因此,Sama决定终止与OpenAI的合作。
在2022年2月下旬,陆陆续续有Sama的员工收到了转岗和裁员的通知。一位员工无奈的表示:“对我们来说,这是一份养家糊口的工作。而现在,仅有30多名工人被迫转到更低薪的岗位,其他人都面临失业。”
今年1月10日,Sama宣布取消所有涉及到敏感内容的工作,并表示不会与Facebook续签价值390万美元的内容审核合同。据了解,Facebook也曾被指控雇佣外包劳工来审核有害内容。
Sama表示,经团队多次讨论后,公司决定剥离自然语言处理和内容审核业务,专注于构建计算机视觉数据标注解决方案。
家园 一个小时挣够中国脱贫标准一天的钱,还要啥自行车? 中国脱贫标准就是一天消费两美元。肯尼亚人每天工作一个小时就脱贫了,还要啥自行车。他们难道比中国人高贵很多么?
通宝推:卡路里,家园 所以说这是个能容纳廉价劳动力的巨大产业啊 不是整天担心产业转移之后中国的劳动力怎么安置么,这不产业来了么
连非洲黑叔叔都能做,这对于普通劳动力能有多大门槛
家园 够呛 机器学习的问题是学一次就够了。人类标注是加速优化过程,让系统更快的找到最优解。当它基本找到的时候,人类标注的意义就越来越小(因为机器的答案和人类越来越接近)。最后机器的答案可能比人类都准确了(人可以偷懒,搞错)。更加要命的是,当它学习完成之后,不用人类了。
就和当年谷歌围棋的原理一样。一开始学习人类棋谱,后来自己学自己。而一旦学完,直接就是巅峰。当年的alpha狗和今天的alpha狗没啥区别。人类没用了,除了跟着学。
- 复 够呛
家园 路要一步一步走,饭一口一口吃 既然现在标注有助于提升,那就搞,不要小搞,要大搞。不要妄想像其他什么人比如印度想走捷径,最后肯定是时间也没省下来,资源也浪费了白忙一场。
通宝推:桥上,家园 gpt真是一个国家的无产阶级可以是另一个国家的人的绝佳例子 标注行业完全就是人工智能的最下游,就像任何雄伟的工业奇观底层都是打灰大猛子一样。
微软用肯尼亚人做标注,就可以规避本国的一些法案,甚至给2美元的时薪在当地都算高薪了。数据标注难免会接触到阴暗内容,由此带来的心理问题可以大方的甩给肯尼亚人,用本国员工出了什么问题还得兜底。
中国要做什么大事只能压榨本国底层,由此带来的一切社会问题都得自己消化。中国的gpt能用上外国劳动力么?刚听说中非得金矿出事了死9个中国人,相比于老牌西方国家,中国还是任重道远啊
家园 百度这次可能要做烈士了, 不成功,肯定死,成功,也死(盈利模式彻底变了),但是还能挣个好名声。
家园 我倒觉得相反,迷茫的百度总算找到方向了 百度「文心一言」的真实内测使用体验如何? - 段小草的回答 - 知乎https://www.zhihu.com/question/589955024/answer/2940079055 看来似乎比发布会上还要好一点。百度难得以一次正面形象出现在公众视野里,这就是对当前的百度最大的意义。
all in ai一直没找到赢利点,要是没有chatgpt打开局面他还得指着遥遥无期的无人驾驶
