主题:【原创】wikipedia架构学习笔记(一)他们的骄傲 -- 羽羊
Wikipedia架构学习笔记
wikipedia毫无疑问是个超大规模的网站,在软件的使用、配置、管理方面亮点无数,而且wikipedia开放的态度对于后来者学习他们的优秀经验非常有帮助,在几个项目中,都多多少少从wikipedia获益,于是把学习的点点滴滴整理一下、记录下来,最近俗务繁多,也不知道什么时候能填完,小羊一定尽快。因为水平有限,所以本文一定挂一漏万,而且错漏之处一定不少,还请各位指正。
一、wikipedia的骄傲
根据wikipedia自己的说法:
Wikipedia has grown rapidly into one of the largest reference web sites,
attracting around 65 million visitors monthly as of 2009.
There are more than 75,000 active contributors working on more than 14,000,000 articles in more than 260 languages.
As of today, there are 3,060,942 articles in English.
Every day, hundreds of thousands of visitors from around the world collectively make tens of thousands of edits and create thousands of new articles to augment the knowledge held by the Wikipedia encyclopedia
技术数据,根据Mark Bergsma的pdf:
30 000 HTTP requests/s during peak-time
3 Gbit/s of data traffic
3 data centers: Tampa, Amsterdam, Seoul
350 servers, ranging between 1x P4 to 2x Xeon Quad-
Core, 0.5 - 16 GB of memory
...managed by ~ 6 people
现在的最新数据
(发文前,小羊很八卦的一台台数了一下 )服务器357台在线,而且排名从Mark Bergsma作报告时的第10名上升到了第六名
)服务器357台在线,而且排名从Mark Bergsma作报告时的第10名上升到了第六名
实时性能数据
实时访问数据
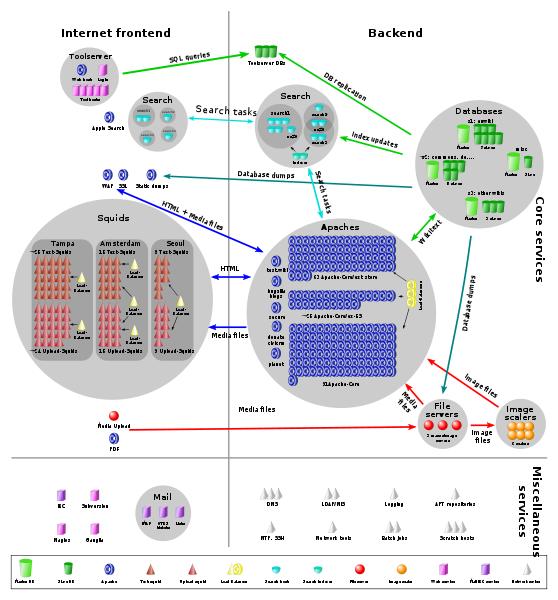
2009年4月5日的架构图(写实风格的,能数出server数量。。。 看到晕倒。。。)
看到晕倒。。。)
){kind=link}
花了多少钱?
wikimedia基金会的08-09财年报告,懂财务的自己看吧
一个致力于知识存储、共享和传播的网站
一个致力于知识存储、共享和传播、达到如此规模的网站
他们有充分的理由骄傲。
本帖一共被 1 帖 引用 (帖内工具实现)
具有知识共产主义原始萌芽的意义
wikipedia技术上大量采用开源社区产品,内容上由全世界共同维护,也许应该说,wikipedia的骄傲也是全人类的骄傲
wikipedia有多少台服务器?上回小羊数了,357台,多少台放在前端接受用户访问请求?没数,谁爱数谁自己数去,人不能太八卦,呵呵,不过肯定不少于100台了,分别组成N个cluster,放置在好几个机房,上次贴了一个wikipedia架构图,相信那个写实风格的架构图,不是小羊一个人晕菜——这TMD简直就是一片服务器的丛林阿。但是,对于用户来说,就算它有百万台server、八百个cluster都不关我事儿,用户只管输入www.wikipedia.org,那么用户访问的时候,指向的是哪里?访问的是哪一个IP?
我们跟着感觉走一回,设想两台服务器,一台就在你们家隔壁,一台在地球的另一端,两台服务器都能够提供你需要的服务,你访问哪一台?
恭喜你,答对了,当然是离你最近的那一台,而且wikipedia就是这么干的。
用户首先遇到的就是wikipedia玩儿的第一个花样——DNS解析
DNS我们都知道是个什么东西——当我们在browser地址栏输入西西河的地址的时候,我们真正要去的,其实不是ccthere.com,而是寂寞。。。不对不对,乱了乱了呵呵,而是205.209.175.100这个ip地址,ip地址才是ipv4网络的根本,browser就是从DNS服务器那里获得了205.209.175.100这个地址,才能把我们扔到河里来的。其实中间还有一步,就是把ccthere.com变成ccthere.com. 看到区别了?(没看到的跟我来——为革命,保护视力,眼保健操,现在开始。)从难记的ip地址,到好记的域名,再到会自动补齐那个小圆点,技术,就是在人类贪得无厌的偷懒欲望中进步嘀。
知道了网站的IP地址,实际上还没有开始访问网站呢,这个时候,wikipedia的花样就已经开始玩儿了。以查询 zh.wikipedia.org 为例:
首先客户端发送查询报文"query zh.wikipedia.org"至DNS服务器,DNS服务器首先检查自身缓存,如果存在记录则直接返回结果。如果记录老化或不存在:
1.DNS服务器向根域名服务器发送查询报文"query zh.wikipedia.org",根域名服务器返回 .org 域的权威域名服务器地址。
2.DNS服务器向 .org 域的权威域名服务器发送查询报文"query zh.wikipedia.org",得到 .wikipedia.org 域的权威域名服务器地址。
3.DNS服务器向 .wikipedia.org 域的权威域名服务器发送查询报文"query zh.wikipedia.org",得到主机 zh 的A记录,存入自身缓存并返回给客户端。
花样就在第二步,看下图,我们实际查询的结果
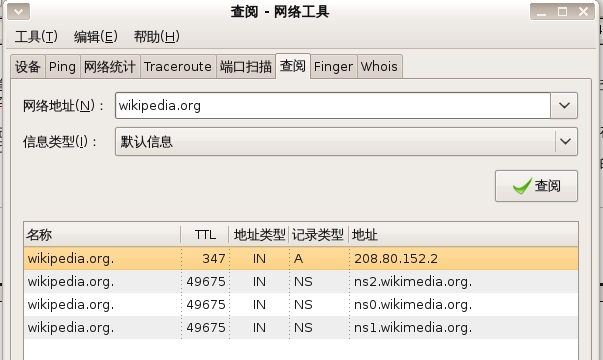
分析一下:A记录的TTL很短,Ns记录地址类型是IN,也就是说,一般情况下,我们本地的DNS服务器不管怎么设置,因为TTL时间实在太短了,本地设置的DNS服务器缓存中 wikipedia.org这个域的解析基本都会从第五列的那三台域名解析服务器获得最新的结果。
wikipedia在他自己的DNS服务器上做了手脚,添加了地理信息设置,这个就是架构图当中所谓GeoDNS。
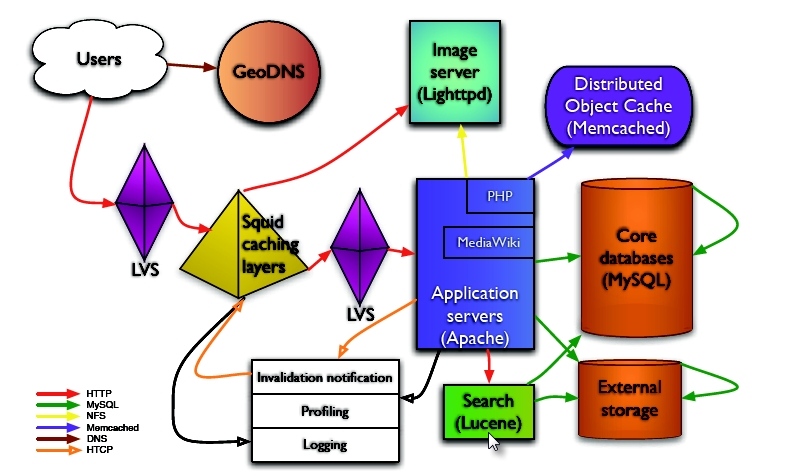
这样一来,整个流程就清晰了,我们访问wikipedia.org,从我们指向的DNS服务器中获取的就是离我们最近的wikipedia服务器IP地址,然后这个地址就被存放到本地缓存中直到我们手工flush或者过期,从而在地域上先对服务器做了一次基于DNS的负载均衡。
小平说:电脑要从娃娃抓起
wikipedia说:提高网站性能要从用户端抓起
其实写到这里,有个疑问:
首先,首尔yahoo机房提供的服务器离线之后,wikipedia现在的机房只有两处,在这种情况下,GeoDNS基于地理信息对于用户的引导,不能说没有用,至少在wikipedia强悍的处理能力和足够的带宽面前,用处不大了;
其次、wikipedia的内容庞大是毫无疑问的,但是其内容却并非对于全部用户均有价值,而是根据语种的分别对用户有价值,语种的分别又天然的和地理信息有关系;
那么,我们可以想象一下:
1、为德语区的用户访问提供服务的server cluster如果存储非德语资料,利用率一定是底下的
2、如果德语区的cluster无法提供用户需要的内容,那么它需要找到最近的服务器获取内容
再看看wikipeida自己的DNS技术说明,有这样一句话“Wikimedia use two separate kinds of DNS servers, authoritative nameservers (that respond to queries from third party nameservers for our domains) and resolvers (that resolve DNS queries for our own servers) ”
我们有理由怀疑GeoDNS对于wikipedia最重要的用处应该在于内容的分布、存储和读取方面。
真的么?
参考:
我这几天有点分神。物联网那个插播需要结束,Twitter只刨了一个小坑,下周接着刨。
先花。周末时,仔细读读,猛烈拍砖。
就等着砖呢,这两天写着写着有点迷茫,好像太蜻蜓点水了,再往细节写,又不知道怎么写,要不就成了抄配置文件了,抓紧砖,要大大的砖。
嘿嘿,我也有插播哦。。。
可能先拟个提纲比较好,要么重点架构,要么专注一些亮点和细节,要么点面结合但有所侧重,各有各的写法。
现在看起来是个巨坑,都2章了,还在门口dns转呢,不过反正我有耐心,在坑里等,就是不出来
主要原因有网络因素,包括带宽、流量限制,错误的路由设置;也有服务器端的因素,如CPU,queue,I/O等。
对此google专门开发了一个工具whyhigh用于诊断这类网络迟延。
http://research.google.com/pubs/pub35590.html
关于地理位置的说法,老哥您说的是对的,我感觉wikipedia综合考虑这些因素更新DNS应该问题不大,但是似乎有几个原因他们没有做:
1、wikipedia接受用户访问的ip不多,但每个ip后头都是一堆堆的server,如果根据带宽,服务器忙闲这些因素,就必须综合这些IP后面cluster的状况,比起现在40行代码实现的简单分配方法,可能略嫌麻烦了
2、负载均衡的方法很多,dns算是一种,按照忙闲分配段位更高,从适用环境来说,后者更适用于cluster中节点与节点之间,如果采用根据忙闲等因素更新dns的方法,必须面临的一个问题就是dns记录在用户端以及其他dns服务器上的缓存问题,尽管可以尽量的降低TTL,但肯定无法实时更新dns记录,这样一来,负载均衡的效果不会太好
所以如果第一步用户和几个接受访问的ip之间,采用复杂的负载均衡分配方法,效费比不好,这可能就是wikipedia没有采用的原因吧。
但是,在wikipeida的cluster当中,肯定负载均衡的方法要多很多花样。。。
另外:
给老哥送宝,我去研究一下google的那玩意儿去再说
这篇文章的出处是我以前几个项目的笔记和心得,因为wikipedia的资料很好弄,所以以前有了问题,就会跑去看看,现在动笔了,草草列了一个提纲,发现笔记当中点状的东西就很薄弱,要往里面补充东西,有的地方,还得搭环境实测一下才敢张嘴,另外,wikipedia确实有些地方我是没看明白的,所以,进度肯定快不了
刨坑真难阿,你们这些人动不动就坑人上千,我才写了两篇就累的上吐下泻,唉,差距是大阿。。。
前几篇还在轨道上,写着写着到最后基本就拆拆补补,能不面目全非就不错呢,^_^。
所以还是当看官好啊。
鼠标一点,花一下就有东东看。
为呢满足我等看官的要求,羊倌你
[IMGA]http://t0.gstatic.cn/images?q=tbn:DVUgvEpCrEvK4M[/IMGA]
现在正在服务器的丛林战斗中。。。
写Flickr的前3篇我差不多看了一个多月的资料,因为网站,mysql,memcache以前没做过,纯粹是纸上谈兵。
你有实战经验应该写的更好一些。