主题:【整理】芯片败局 -- 拿不准
另外我什么时候说过中国靠巴结美国才能做生意的。
中美两国现在每年的贸易额这么大,说明什么,至少双方的商人信誉信用都是不错的吧,美国要脱钩是政治问题。
河里人没她有见识当然是默认的情况。没有姚明个高不丢人,没有董明珠有见识更不丢人。
没人会在大学课堂里说,你们那,身为大学生都不如习近平这样一个胖老汉有见识。因为习近平主要标签是国家领导人,不是胖老汉。虽然说他是胖老汉符合事实,不算物理性说谎。
但是,不如董明珠有见识,和董明珠每句话都是对的,没有必然联系。比如世界上最高明的骗子,肯定是成功人士,肯定见识高,但是这不意味着他的每句话都可信。
美西是好客户,在大量外贸企业的不能改变的环境下,当然是对的。就跟很多韩国人觉得部队火锅是好吃的一样。如果一个韩国人感到丢脸,该骂的是为什么当时韩国民众那么贫穷,而不是去骂他们格调低下。他们不是在日常满汉全席和部队火锅中选的后者。如果一美元相当于一人民币元,外贸企业肯定不会再觉得美西是好客户了。
脱钩这个词,从来都是美国人在说。
我从来没有见过任何一个中国人,说要主动跟美国脱钩。
----------
美国人要脱钩,凭啥要中国人反思?
反思我们不应该发展这么快?我们应该跟菲律宾缅甸学习?
反思我们不应该发展高科技,华为就不应该做手机?
还是反思我们对美国跪得不够彻底,应该签一个卖国协议,彻底出卖台湾,新疆和西藏?
-----
我真是想破脑袋,也想不出中国人应该做啥反思?
求反思党不要这么阴阳怪气,直接给一个答案,拿一个什么样得卖国条约出来,可以让美国人不要脱钩。
他( @hwd99 )文章虽然很多,而且多数很长,但是内容大同小异,读几篇就领会了。你要问我,对当前困境的解决方案,很简单:
1 更改兑换汇率。一美元相当于一人民币元。其他外币汇率相应跟着改。
2 法人和中国籍自然人,不许转移资金出境。除非总理本人亲自批准。
3 外籍自然人,终生只有一次资金出境机会,每人限额北京二环一套房的价格。
4 购买外国产品,必须严格遵照国家进口目录来。由国务院订目录,以自然资源和中国急缺技术、装备为主,严禁奢侈品和非必需品。该目录每年一更新。
大语言模型好几家族谱,谷歌,脸书等都自己有,一鸣惊人的是OpenAI,没有开源,后来脸书为了搞乱市场,故意流出自己的模型,这里的开源与linux也不一样,因为没有参数,开源也没用,脸书流出的llama是参数齐全的,可以拿来即用,然后全世界都在拿这个在那里调试改进。后来脸书就正式开源llama 2了,不玩流出这种把戏了。
这是类似chatgpt的大语言模型而言,实事求是的说,除了openAI的chatgpt4,其他包括脸书开源的,也包括openAI自己的chatgpt3.5的性能都与其有明显差距,随便任何人用几个问题一试就可以看出,都不用玩复杂的。 后来所谓AI恐惧症加上各种立法限制大讨论主要也是因由GPT 4带出来的,因为chatgpt 4版的表现确实比较吓人。
所有今天真正市面上频繁发布的大模型都是llama开源的后代,有个人的,机构的,也有企业级的,也包括微软的大模型产品。闭源的话只有那么几家传统AI企业偶尔升个级,比如谷歌等,但因为性能都比不上人家公开使用(付费)的OpenAI家的gtp4,所以浪花都不大。但不是说不能用,其实闭源做的比较好的性能差距不是很大,在chatgpt4一炮而红之前也有很多应用,有很大的市场潜力,商业产品也多。 只不过现在大家都一窝蜂去只看gpt4了,最后那一点差距决定了大模型的一些应用与潜在的产品。 相当于说,比起哺乳动物,十岁幼童的智力都高了几个数量级,但是十岁孩子遇到30岁骗子,肯定是见一个拐一个的差距。基本上其他大语言模型目前与chatgtp4的差距就是这么个体位的间隔。
大模型的所谓训练,语料(corpus,很喜欢语料这个翻译词)都与模型架构本身一样对模型的性能有决定性影响,这也是为什么开源大模型架构本身没有太大意义的原因,不但训练的耗材是个门槛,就是语料的选择本身都是未知数。
脸书meta开源的那个llama是连架构带参数一起给了,所以最大的门槛被解决了,而且原始版是没有经过政治正确调试的,可以胡说八道 😁 不过提起智商来比chagtp4差的不少。比如问题个”老张是小张的爹,老张与小张谁先出生的“,完了,就这么个问题十个模型可以给出三十种解答,而且90%没答对😄 这种模型用起来那叫一个不踏实。
就这么个开源模型,全世界从阿联酋到美国海军陆战队,都在抢着调试改进,唯一的好处是可以压缩小版本在手提电脑上用,甚至未来还可能在手机上用,不用联网自带十万个为什么,吸引力很大,不过智障也很显著 😁
当然这个政治正确调试不是唯一造成智障的原因,其他大模型比如绘画的那些,就比较不容易受到这些语言范围内的调试影响。
不过说起国内引进的话,llama比较现成的开源,参数与广大开发调试群体的数量庞大,类似linux,不用白不用。 这是对于一些本身资源有限的企业级应用来说的,你自己开发估计还赶不上llama的进步与应用配套的广度与深度。 当然大企业甚至国家级的资源,就另当别论了,自己完全可以从头干起,所有大模型与AI科研都可是有paper的,甚至开源的程序都可以找到,这些不是门槛,更有可能的是大企业自身就是这些进步的推手,比如谷歌,国内也有几家,但是大模型的科研与训练对自身资源的口袋深度是有很高要求的,确实不是一般企业玩得起的。
客观的说,国产大模型没有任何道理比OpenAI的差,但同理也无法解释谷歌的大模型为什么表现不如chatgpt4. 这里面包括了模型本身架构,基础计算设施,资源投入,训练方法,以及语料,除了第一条之外,后几条几乎都是不开源的,属于核心竞争力。其中尤其要重视语料的质量与选择,我前面说过llama开源后很多上万种各种调试,后期训练等,其中主要区别都是在语料方面,因为前期训练成本太高,一个30亿参数的袖珍版小模型就要投入上百万美刀的训练成本。但语料的提高可以得到非常明显的性能改善,这现在基本是公认的了。
中文语料的质量与选择无疑是个工作量要超过英语,本质上是文字信息在互联网与文献中的普遍以英文存在的原因。 相反在算法领域,在模型架构上,因为中国人才在AI科研领域的广泛参与,我个人认为可能还真不存在中美差距。 但是在后几个领域,因为看不到paper,而且基本上都是各家关起门来闷头干,所以很难估量。 不恰当的比方,类似闭源软件,你说中国的顶级企业软件水平与资源,就是从头开发个视窗 windows10操作系统,理论上应该是可以做到的,但是这么多年了不但中国全世界也没人干成这事,就那么看着微软得瑟。 说明这后面的工程量与难度还是很大的。
就是那个copyright问题,目前是大模型领域的重大法律纠纷定时炸弹,chatgpt已经成了众矢之的,好几个大案都在筹备中,准备好好干一票。 这个问题的发展无疑会不但对OpenAI自身经营有重大影响,对大模型商业模式与性能调试,都是继政治正确紧箍咒之后的另一个重大转折点。然后,中国没有这方面的顾虑,虽然对走向西方市场有影响,但反正脱钩了,市场面向亚非拉,可以爽快的把知识产权这顶帽子甩得远远的了😁
欧美大环境目前是对AI非常不友好,从民间到政府,都有强大的怀疑不信任, 取代工作是主要担忧,当然大企业与资本是AI背后的强大推手,但在AI矛盾上会不会引发21世纪西方全球党控制以外的新一轮共产主义运动,这是个很有看点的地方。
也就是7nm制程
爆料人刘庆峰,不认识的可以随便搜索一下看他是谁。
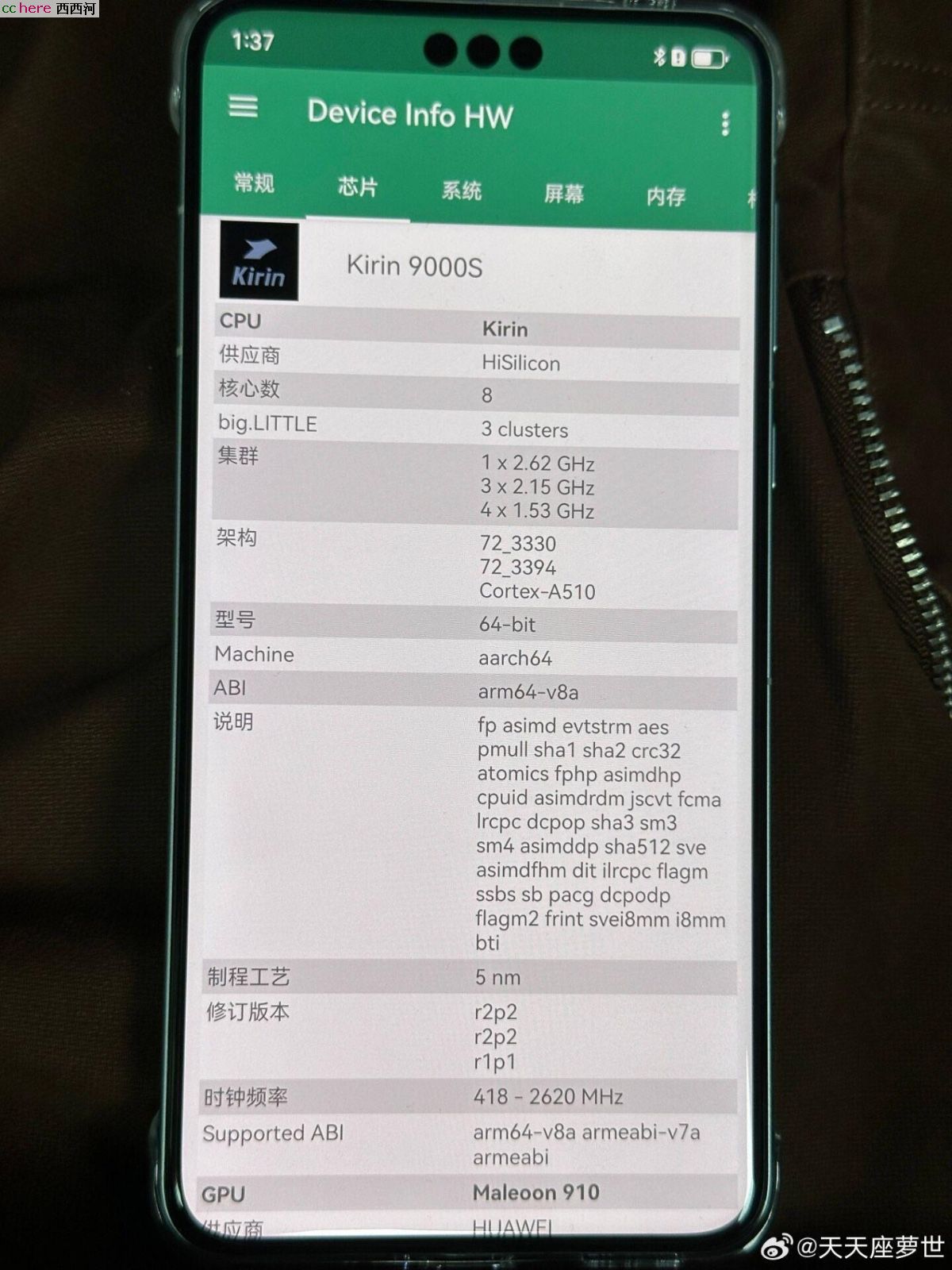
Mate 60 Pro 于 8 月 29 日 12 点 08 分在华为商城提前开售!麒麟9000S自研7nm芯片(也有说5nm),自研GPU,5G!!!今天也给了美国商务部长一个大惊喜,12年前的美国防部长到访中国,恰巧当日歼20首飞,今日美商务部长与强总会面,恰巧Mate60今天提前发售,哈哈!
7nm足够了!
科技战还是我们赢了,虽然没抢到Mate60,但还是小酌一杯!
“一场重头戏要上演”
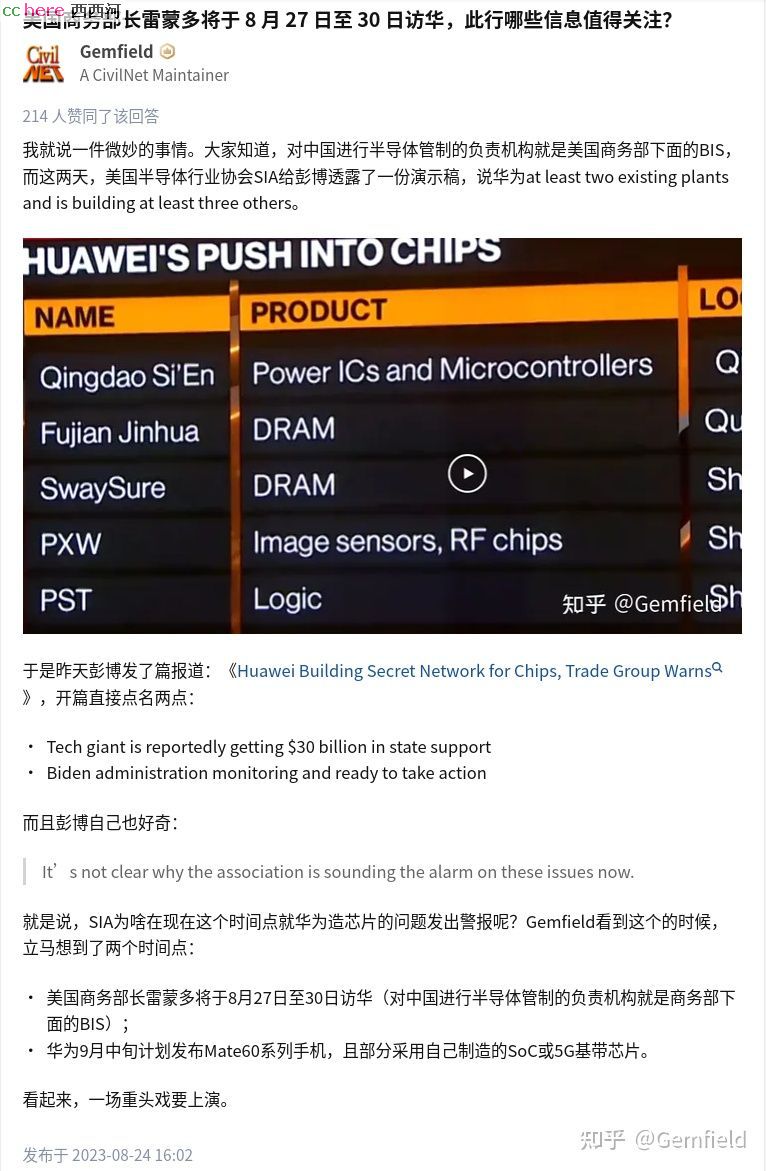
今天下午,OPPO正式发布了折叠屏Find N3 Flip,原以为今天只有这一款手机发布。但华为中午突然宣布Mate60Pro提前发售,这也是有史以来旗舰机第一次,在发布会前半个月把所有信息和配置都爆出来(毕竟都直接发售了)。
至于为什么这么突然发布旗舰新机,华为终端官博官宣时表示,主要是庆祝华为 Mate 系列手机今天累计发货达到一亿台。为了感谢消费者的支持与热爱,华为推出了“HUAWEI Mate 60 Pro 先锋计划”,让大家抢鲜体验。
纯属巧合
高兴的太早了
如果真是中芯搓出来的,即使良品率不高,也真是巨大进步。
感觉甚至比J20横空出世还不可思议

9000S横空出世,7nm非美线。美国这还玩个屁啊,我还当八年抗战三年解放战争,这尼玛直接三大战役都开打了。
intel可以14nm+++,我们哪怕Skylake,E5V4量产,除了少数DIY打游戏用户,从家用机到办公室到90%企业的机房都够够的。GPU部分步到2018年很成熟的三星12nm级别,老黄的2080ti / GV100,硬件上游戏玩家也可以95%满足(steam性能排行)。